Benchmark Examples

In this paper, we introduce OmniEval, a benchmark for evaluating omni-modality models like MiniCPM-O 2.6, which encompasses visual, auditory, and textual inputs. Compared with existing benchmarks, our OmniEval has several distinctive features: (i) Full-modal collaboration: We design evaluation tasks that highlight the strong coupling between audio and video, requiring models to effectively leverage the collaborative perception of all modalities; (ii) Diversity of videos: OmniEval includes 810 audio-visual synchronized videos, 285 Chinese videos and 525 English videos; (iii) Diversity and granularity of tasks: OmniEval contains 2617 question-answer pairs, comprising 1412 open-ended questions and 1205 multiple-choice questions. These questions are divided into 3 major task types and 12 sub-task types to achieve comprehensive evaluation. Among them, we introduce a more granular video localization task named Grounding. Then we conduct experiments on OmniEval with several omni-modality models. We hope that our OmniEval can provide a platform for evaluating the ability to construct and understand coherence from the context of all modalities. Codes and data could be found at https://omnieval-benchmark.github.io/.
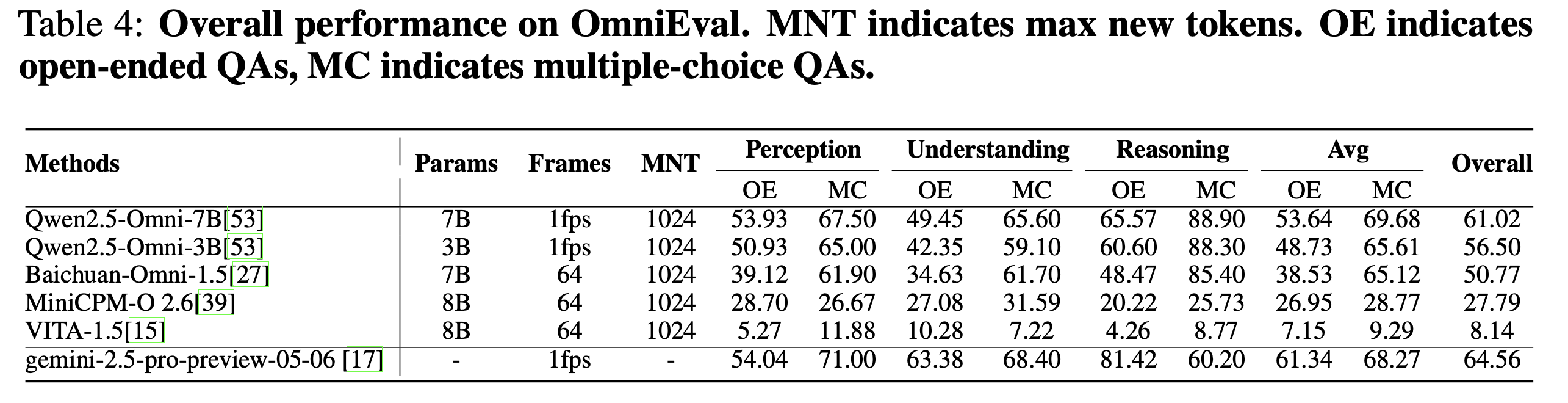
Overall performance on OmniEval. The experimental results indicate that existing models face significant challenges in understanding real-world information.
@misc{zhang2025omnievalbenchmarkevaluatingomnimodal,
title={OmniEval: A Benchmark for Evaluating Omni-modal Models with Visual, Auditory, and Textual Inputs},
author={Yiman Zhang and Ziheng Luo and Qiangyu Yan and Wei He and Borui Jiang and Xinghao Chen and Kai Han},
year={2025},
eprint={2506.20960},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.20960},
}